
Top 10 errors in R and how to fix them
- Introduction
- 1. Unmatched parentheses, curly braces, square brackets or quotes
- 2. Using a function that is not installed or loaded
- 3. Typos in function, variable, dataset, object or package names
- 4. Missing, incorrect or misspelled arguments in functions
- 5. Wrong, inappropriate or inconsistent data types
- 6. Forgetting the + sign in ggplot2
- 7. Misunderstanding between = and ==
- 8. Undefined columns selected
- 9. Problem when importing or using the wrong data file
- 10. Problem when using the $ operator
- Warnings
- Conclusion

Introduction
If you are just starting with R, you will often encounter errors in your code which prevent it to run. I remember when I was just starting to use R, errors in my code were so frequent that I almost gave up learning this programming language. I even recall that I went back to Excel a few times to finish my analyses because I could not find what was causing the issue.
Fortunately, I forced myself to continue despite the difficulties of the beginning. And today, even if I still encounter errors almost every time I write R code, with experience and practice, it takes less and less time to fix them. If you are also struggling at the beginning, rest assured, it is normal: everyone experiences some frustration when learning a new programming language (and this is the case not only with R).
In this post, I highlight the 10 most common errors in R and how to fix them. Of course, errors depend on your code and your analyses, so it is impossible to cover all of them (and Google does it way better than me). However, I would like to focus on some common syntax mistakes that are frequent when learning R, and which can sometimes take a long time to be fixed before realizing that the solution is right in front of our eyes.
This collection is based on my personal experience and the errors encountered by my students when I teach R. This list being non-exhaustive, feel free to comment (at the end of the post) with errors you often face when using R.
For each error, I provide examples and solutions to fix them. I also mention a couple of warnings (which are, strictly speaking, not errors) at the end of the post.
1. Unmatched parentheses, curly braces, square brackets or quotes
One rather trivial but still quite frequent error is a missing parenthesis, curly brace, square bracket or quotation mark.
This type of error is applicable to many programming languages. In R, for instance:
## missing a closing parenthesis:
mean(c(1, 7, 13)
## missing a curly brace before "else":
x <- 7
if(x > 10) {
print("x > 10")
else {
print("x <= 10")
}
## missing a square bracket:
summary(ggplot2::diamonds[, "price")
## missing a closing quote in 2nd element:
grp <- c("Group 1", "Group 2)
grpThese errors are easy to detect when the code is basic, but can become much harder to spot with a more complex code, for instance:1
for (i in y) {
for (j in x) {
p <- ggboxplot(dat,
x = colnames(dat[j]), y = colnames(dat[i]),
color = colnames(dat[j]),
legend = "none",
palette = "npg",
add = "jitter"
)
print(
p + stat_compare_means(aes(label = paste0(..method.., ", p-value = ", ..p.format..),
method = method1, label.y = max(dat[, i], na.rm = TRUE)
)
+ stat_compare_means(comparisons = my_comparisons, method = method2, label = "p.format")
)
}Thankfully, if you use RStudio,2 a closing parenthesis, curly brace, square bracket or quotation mark will automatically be written when you open one.
Bear in mind that when installing a package, you must use (single or double) quotation marks around the package’s name:
## NOT correct:
install.packages(ggplot2)## Error in install.packages : object 'ggplot2' not foundInstead, write one of the two following options:
# install.packages("ggplot2")
# install.packages('ggplot2')Solution
The solution of course is to simply match all opening parentheses, curly braces, square brackets and quotation marks with their closing counterparts:
mean(c(1, 7, 13))## [1] 7x <- 7
if (x > 10) {
print("x > 10")
} else {
print("x <= 10")
}## [1] "x <= 10"summary(ggplot2::diamonds[, "price"])## price
## Min. : 326
## 1st Qu.: 950
## Median : 2401
## Mean : 3933
## 3rd Qu.: 5324
## Max. :18823grp <- c("Group 1", "Group 2")
grp## [1] "Group 1" "Group 2"Also, make sure:
- to correctly place commas:
## NOT correct (misplaced comma):
c("Group 1," "Group 2")## Error: unexpected string constant in "c("Group 1," "Group 2""## also NOT correct (missing comma):
c("Group 1" "Group 2")## Error: unexpected string constant in "c("Group 1" "Group 2""## correct:
c("Group 1", "Group 2")- you do not mix single and double quotation marks for the same element:
## NOT correct:
c("Group 1')
## correct:
c("Group 1")
## also correct:
c('Group 1')Note that c('Group 1', "Group 2") does not throw an error but for consistency, it is not recommended to mix single and double quotes within the same vector.
2. Using a function that is not installed or loaded
If you encounter the following error: “Error in … : could not find function ‘…’”, for example:

it means you are trying to use a function belonging to a package which is not yet installed or loaded.
Solution
To solve this error, you have to install the package (if it is not installed yet) and load it with the install.packages() and library() functions, respectively:
## install package:
install.packages("ggplot2")
## load package:
library(ggplot2)If you are not sure about the usage of these two functions, see more details about installing and loading a package in R.
3. Typos in function, variable, dataset, object or package names
Another common mistake is to misspell a function, a variable, a dataset, an object or a package’s name, for example:
## typo in function name:
maen(c(1, 7, 13))## Error in maen(c(1, 7, 13)) : could not find function "maen"## typo in variable name:
summary(ggplot2::diamonds[, "detph"])## Error: Column `detph` doesn't exist## typo in dataset name:
data <- data.frame(
x = rnorm(10),
y = rnorm(10)
)
summary(dta[, 2])## Error in summary(dta[, 2]) : object 'dta' not found## typo in object name:
test <- c(1, 7, 13)
mean(tset)## Error in mean(tset) : object 'tset' not found## typo in package name:
library("tydiverse")## Error in library("tydiverse") : there is no package called ‘tydiverse’Solution
Make sure that you correctly spell all your functions, variables, datasets, objects and packages:
Note that R is case sensitive; mean() is considered different than Mean() for R!
mean(c(1, 7, 13))## [1] 7summary(ggplot2::diamonds[, "depth"])## depth
## Min. :43.00
## 1st Qu.:61.00
## Median :61.80
## Mean :61.75
## 3rd Qu.:62.50
## Max. :79.00data <- data.frame(
x = rnorm(10),
y = rnorm(10)
)
data[, 2]## [1] 1.3048697 2.2866454 -1.3888607 -0.2787888 -0.1333213 0.6359504
## [7] -0.2842529 -2.6564554 -2.4404669 1.3201133test <- c(1, 7, 13)
mean(test)## [1] 7library(tidyverse)## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.3 ✔ readr 2.1.4
## ✔ forcats 1.0.0 ✔ stringr 1.5.0
## ✔ ggplot2 3.4.3 ✔ tibble 3.2.1
## ✔ lubridate 1.9.2 ✔ tidyr 1.3.0
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsIf you are sure that you correctly spelled an object, a function or a dataset but you still have an error stating that “object ‘…’ is not found”, make sure that you defined your object/function/dataset before calling it!
It often happens that a student asks me to come to his/her computer because he/she runs the exact same code than me, but cannot make it work. Most of the time, if his/her code is indeed exactly the same than mine, he/she simply has not executed a object/function/dataset before running the code which includes that object/function/dataset. In other words, he/she simply tries to use an undefined object or variable.
Remember that writing code in a R script (contrarily to the console) does not mean it is compiled. You actually have to run it (by clicking on the Run button or using the keyboard shortcut) in order the code to be executed and used later. If you are still struggling with this, see the basics of R and RStudio.
4. Missing, incorrect or misspelled arguments in functions
Most R functions require arguments. For example, the rnorm() function requires at least the number of observations, specified via the argument n.
Your code will not run if you do not specify compulsory arguments, or if incorrectly specify an argument. Moreover, the result might not be what you expect if you misspell an argument:
## missing compulsory argument:
rnorm()## Error in rnorm() : argument "n" is missing, with no default## incorrect argument:
rnorm(n = 3, var = 1)## Error in rnorm(n = 3, var = 1) : unused argument (var = 1)## misspelled argument:
mean(c(1, 7, 13, NA), narm = TRUE)## [1] NAThe last piece of code does not throw an error, but the result is not what we want.
Solution
To solve these errors, make sure to specify at least all compulsory arguments of the function, and the correct ones:
- In
rnorm(), it is the standard deviation,sd, which can be specified in addition to the number of observationsn(instead of the variancevar). - Removing
NAis done withna.rm(instead ofnarm).
rnorm(n = 3, sd = 1)## [1] -0.3066386 -1.7813084 -0.1719174mean(c(1, 7, 13, NA), na.rm = TRUE)## [1] 7If you do not know the arguments of a function by heart, you can always check the documentation with ?function_name or help(function_name), for example:
?rnorm()
## or:
help(rnorm)5. Wrong, inappropriate or inconsistent data types
There are several data types in R, the main ones being:
- Numeric
- Character
- Factor
- Logical
You know that some operations and analyses are possible and appropriate only with some specific types of data.
For example, it is not appropriate to compute the mean of a factor or character variable:
gender <- factor(c("female", "female", "male", "female", "male"))
mean(gender)## Warning in mean.default(gender): argument is not numeric or logical: returning
## NA## [1] NALikewise, although it is technically possible, it makes little sense to draw a barplot of a quantitative continuous variable because in most cases, the frequency will be 1 for each value:
barplot(table(rnorm(10)))
(By the way, if your data is not already displayed in the form of a table, do not forget to add table() inside the barplot() function.)
Solution
Make sure to use the appropriate operation and type of analysis depending on the variable(s) of interest.
For example:
- for factor variables, it is more appropriate to compute frequencies and/or relative frequencies, and draw barplots
- for quantitative continuous variables, it is more appropriate to compute the mean, median, etc. and draw histograms, boxplots, etc.
- for logical variables, the mean,3 a frequency table and a barplot are appropriate
- for character variables, word clouds are the most appropriate (unless the variable can be considered as a factor variable because there are not too many different levels)
We now illustrate the examples in R:4
## factor:
table(gender)## gender
## female male
## 3 2prop.table(table(gender))## gender
## female male
## 0.6 0.4barplot(table(gender))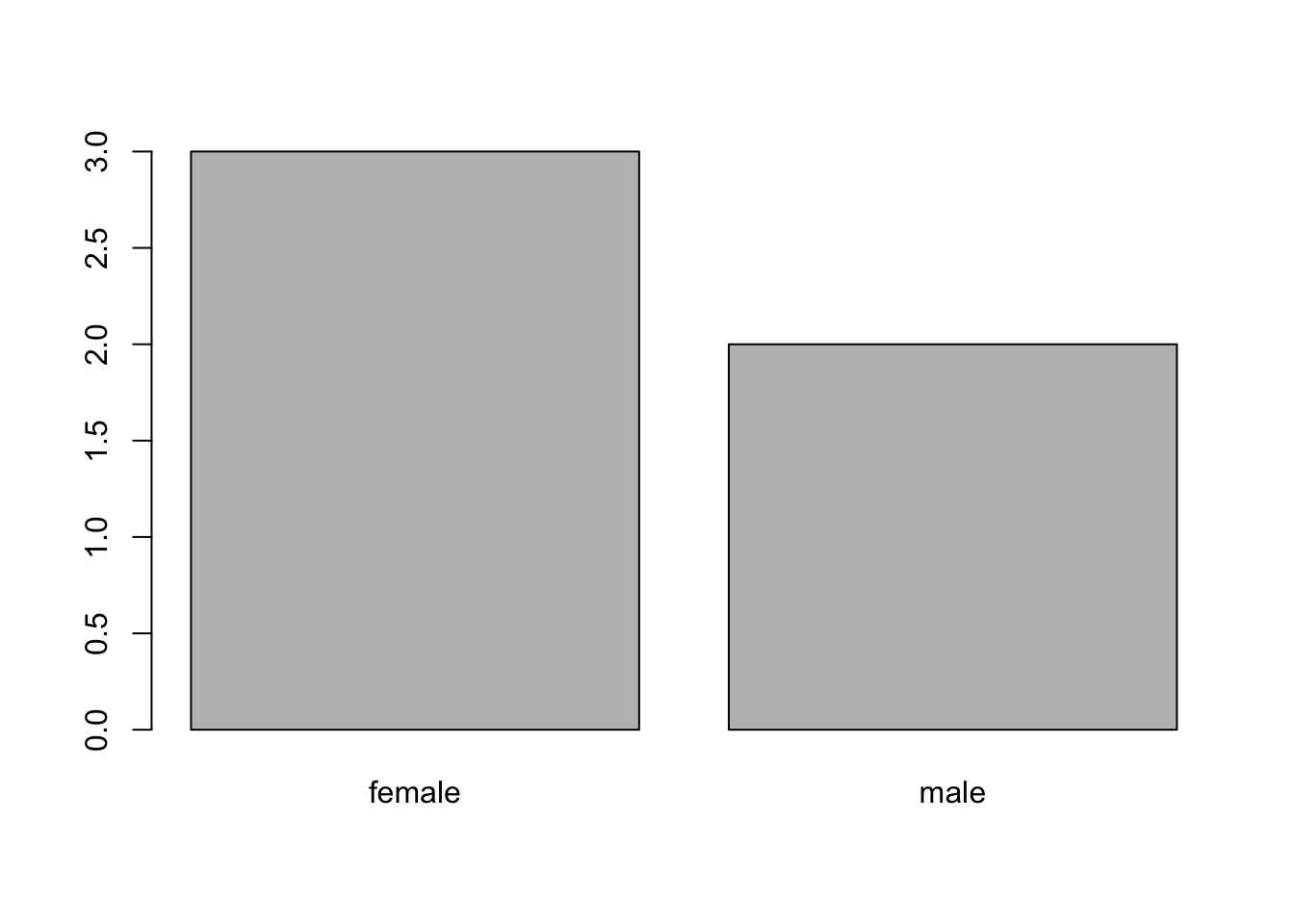
## quantitative continuous:
x <- rnorm(100)
summary(x)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -2.99309 -0.74143 0.01809 -0.08570 0.58937 2.70189par(mfrow = c(1, 2)) ## combine two plots
hist(x)
boxplot(x)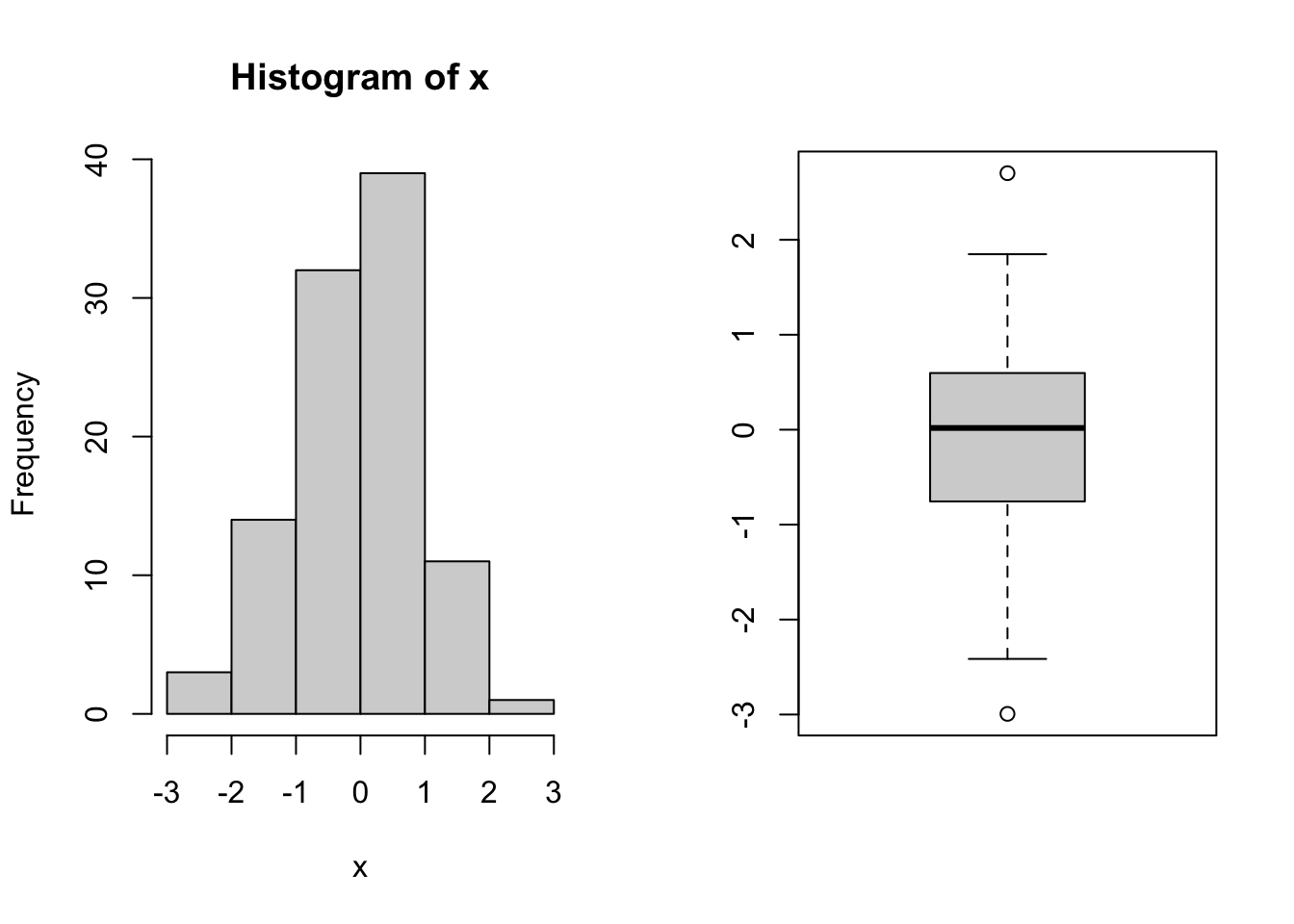
## logical:
x <- c(TRUE, FALSE, FALSE, TRUE, TRUE)
mean(x)## [1] 0.6table(x)## x
## FALSE TRUE
## 2 3barplot(table(x))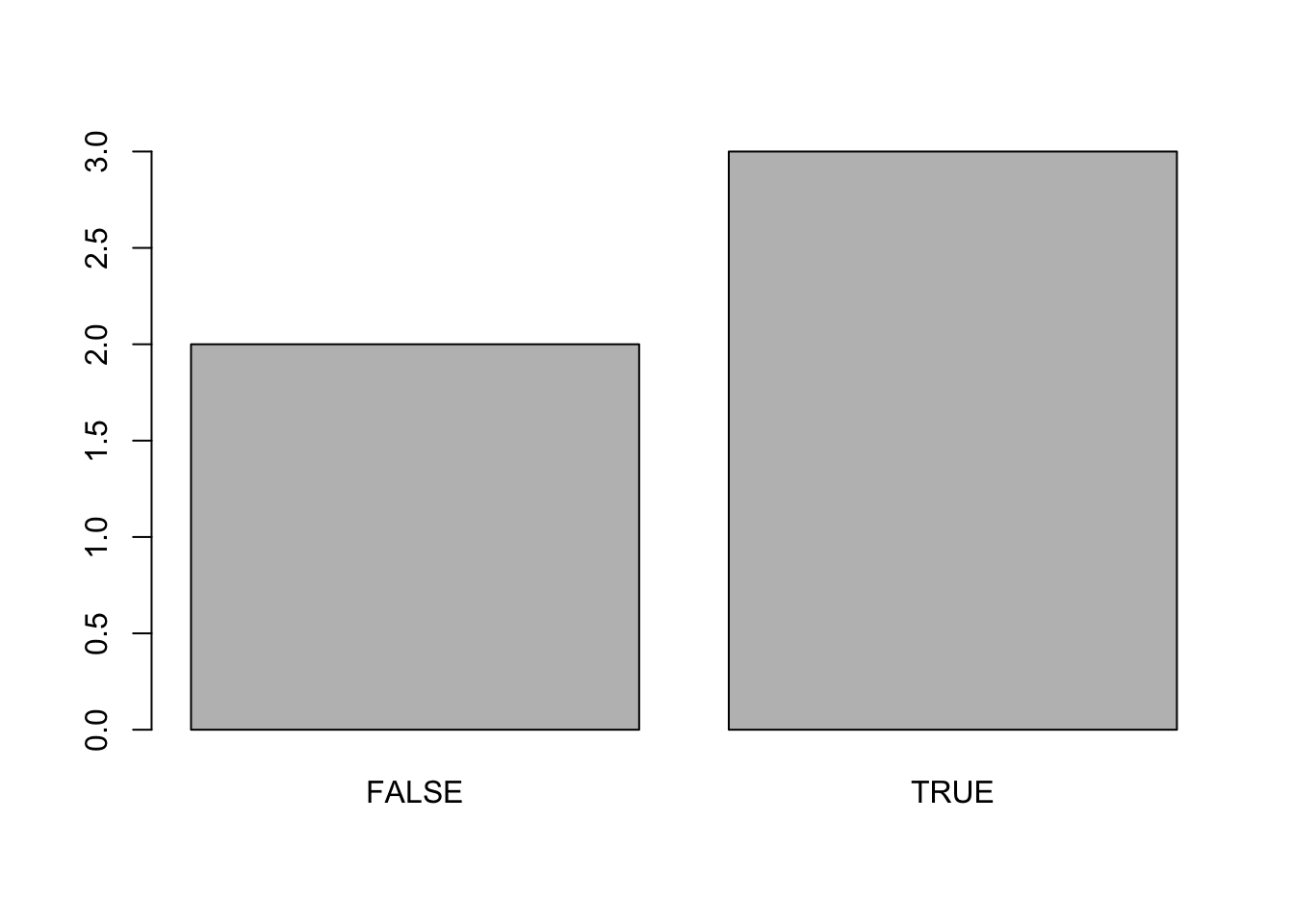
For the interested reader, see the most common descriptive statistics in R for different types of data.
Note that, as for descriptive statistics, the choice of the statistical test depends on the variable’s type. See this flowchart to help you in selecting the most appropriate statistical test depending on the number of variables and their types.
An error linked to the one mentioned above is inconsistent data type. See it in practice with the following example:
x <- c(2.4, 3.7, 5.1, 9.8)
class(x)## [1] "numeric"y <- c(2.4, 3.7, 5.1, "9.8")
class(y)## [1] "character"As you can see, vector x is numerical, whereas vector y is in the form of character. This is due to the fact that the last element of y is surrounded with quotation marks (and thus considered as a string instead of a numerical value), so the entire vector takes the character form.
This can happen when you import a dataset into R and one or several elements of a variable are not encoded correctly. This leads to the entire variable to be considered as a character variable by R.
To avoid this, it is a good practice to check the structure of your dataset (with str()) after importing it to make sure all your variables have the desired format. If not, you can either correct the values in the initial file or change the format in R (with as.numeric()).
6. Forgetting the + sign in ggplot2
If you just learned to use the ggplot2 package for your visualizations (and I highly recommend it!), a common mistake is to forget the + sign.
You know that a visualization made with ggplot2 is constructed by adding several layers:
## load package:
library(ggplot2)
## first layer, the dataset:
ggplot(data = diamonds) +
## second layer, the aesthetics:
aes(x = cut, y = price) +
## third layer, the type of plot:
geom_boxplot() +
## add more layers:
theme_minimal()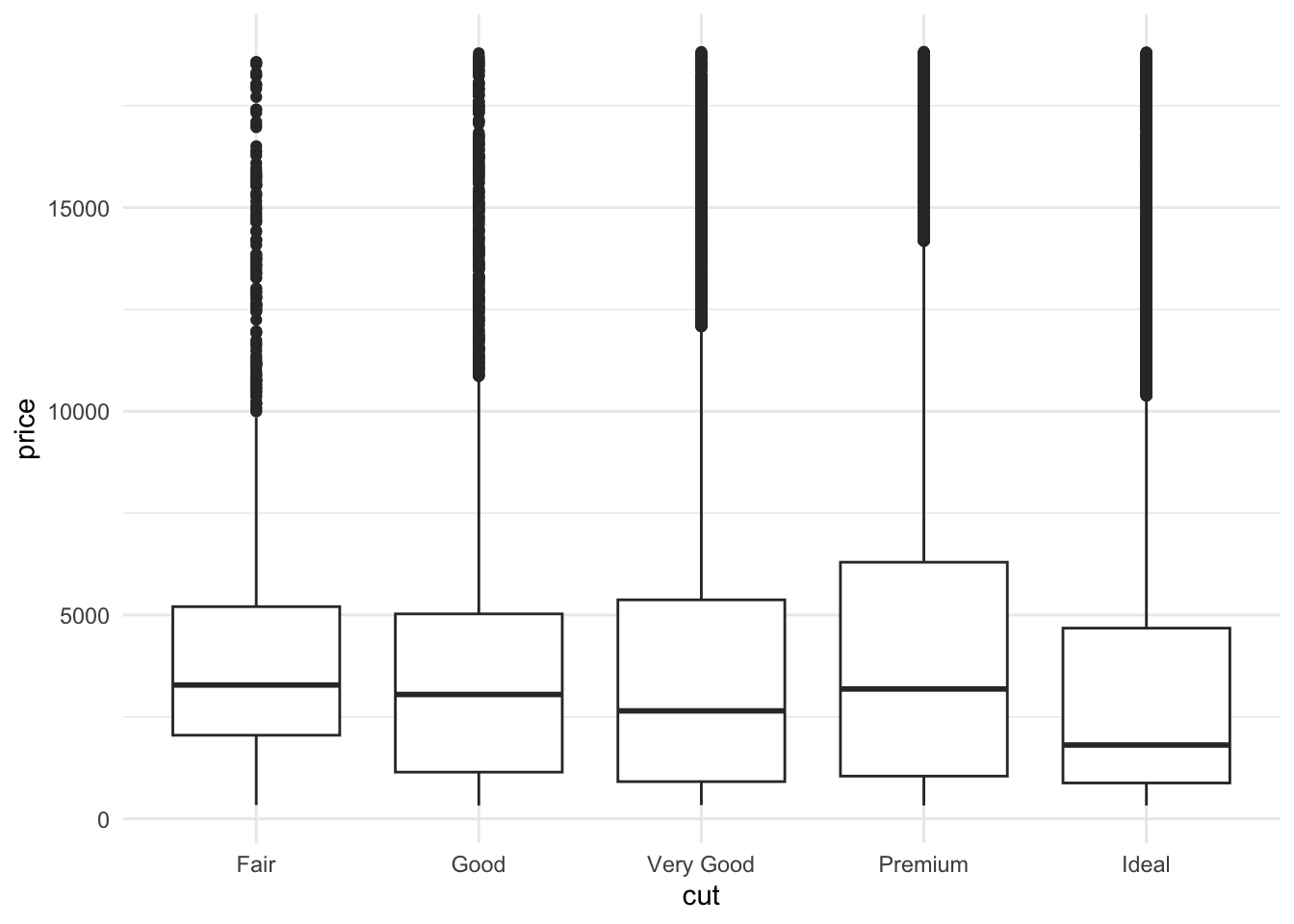
Solution
For all your graphics with ggplot2, do not forget to add a + sign after each layer except the last one.
7. Misunderstanding between = and ==
Assignment in R can be done in three ways, from the most to the least common:
<-=assign()
The second method, that is =, should not be confused with ==.
Indeed, assigning an object (with any of the three above methods) is used to save something in R. For example, if we want to save the vector (1, 3, 7) and rename that vector x, we can write:
x <- c(1, 3, 7)
## or:
x = c(1, 3, 7)
## or:
assign("x", c(1, 3, 7))When executing this piece of code, you will see that the vector x of size 3 appears in the tab “Environment” (the top right panel if you use the default view of RStudio):
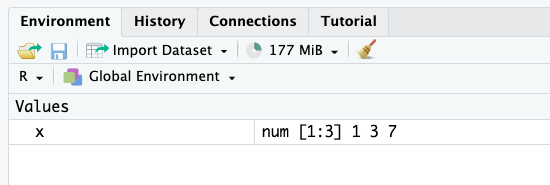
From now on, we can use that vector simply by calling it by its name:
x## [1] 1 3 7By no means, you can assign an object with ==:
## NOT correct if we want to assign c(1, 3, 7) to x:
x == c(1, 3, 7)So you are wondering, when would we need to use ==? Actually, it is used when you want to use an equal sign.
I understand that it may be abstract and confusing at the moment, so let’s suppose the following two scenarios as examples (which are the two most common cases when we use ==):
- we want to check whether an assigned object or variable respects some conditions, and
- we want to subset a dataframe based on one or several conditions.
For these examples, suppose a sample of 5 children:
## create dataframe:
dat <- data.frame(
Name = c("Mary", "Linda", "James", "John", "Patricia"),
Age = c(7, 10, 3, 9, 7),
Gender = c("Girl", "Girl", "Boy", "Boy", "Girl")
)
## print dataframe:
dat## Name Age Gender
## 1 Mary 7 Girl
## 2 Linda 10 Girl
## 3 James 3 Boy
## 4 John 9 Boy
## 5 Patricia 7 GirlLet’s now write different pieces of code for these two scenarios to illustrate them:
- We want to check whether the variable
Ageis equal to the vector(1, 2, 3, 4, 5):
dat$Age == 1:5## [1] FALSE FALSE TRUE FALSE FALSEWith this code, we ask whether the first element of the variable Age is equal to 1, the second element of the variable Age is equal to 2, and so on. The answer is of course FALSE, FALSE, TRUE, FALSE and FALSE since only the third child has an age equal to 3 years.
- We want to know which of our 5 sampled children are girls:
dat$Gender == "Girl"## [1] TRUE TRUE FALSE FALSE TRUEThe results show that the first, second and fifth children are girls, while the third and fourth children are not girls.
If you write any of these two lines:
## this overwrites Age and Gender:
dat$Age = 1:5
dat$Gender = "Girl"You actually overwrite the Age and Gender variables, such that our 5 children will have an age from 1 to 5 (1 year for the first child, up to 5 years for the fifth child) and all of them will be girls.
- Now suppose we want to subset our dataframe based on a condition, namely, we want to extract only the children who are 7 years old:
subset(dat, Age == 7)## Name Age Gender
## 1 Mary 7 Girl
## 5 Patricia 7 GirlIf you do not want to use the subset function, you can also use square brackets:
dat[dat$Age == 7, ]## Name Age Gender
## 1 Mary 7 Girl
## 5 Patricia 7 GirlAs you can see in the previous examples, we do not want to assign anything. Instead, we are asking “is this variable or vector equal to something else?”. For that specific need, we use ==.
So to sum up, for technical reasons and in order to distinguish between the two concepts, R uses = for assignments, and == for the equality sign. Make sure to understand the difference between the two to avoid any errors.
8. Undefined columns selected
If you are used to subset dataframes with square brackets, [], instead of the subset() or filter() functions, you may have faced the error “Error in [.data.frame(…) : undefined columns selected”.
This occurs when R does not understand the column you want to use while subsetting the dataset.
Considering the same sample of 5 children introduced earlier, the following code will throw an error:
dat[dat$Age == 7]## Error in `[.data.frame`(dat, dat$Age == 7) : undefined columns selectedbecause it does not specify the column dimension.
Solution
Remember that dataframes in R have two dimensions:
- the rows (one for each experimental unit), and
- the columns (one for each variable)
and in that particular order (so row first, then column)!
Since dataframes have two dimensions, R expects two dimensions when you call dat[].
In particular, it expects the first and then the second dimension, separated by a comma:
dat[dat$Age == 7, ]## Name Age Gender
## 1 Mary 7 Girl
## 5 Patricia 7 GirlThis code means that we are extracting all rows where Age is equal to 7 (first dimension, i.e. before the comma), for all variables of the dataset (since we did not specify any column after the comma).
For the interested reader, see more ways to subset and manipulate data in R.
9. Problem when importing or using the wrong data file
Importing a dataset in R can be quite challenging for beginners, mainly due to the misunderstanding about the working directory.
When importing a file, R will not search for the file in all your folders of your computer. Instead, it will look only in one specific folder. If your dataset is not inside that folder, it will result in an error such as “cannot open file ‘…’: No such file or directory”:

To fix this, you must specify the path to the folder where your dataset is located. In other words, you need to tell R in which folder you want it to work, hence the name working directory.
Setting the working directory can be done with the setwd() function or via the “Files” tab in the lower right panel of RStudio:
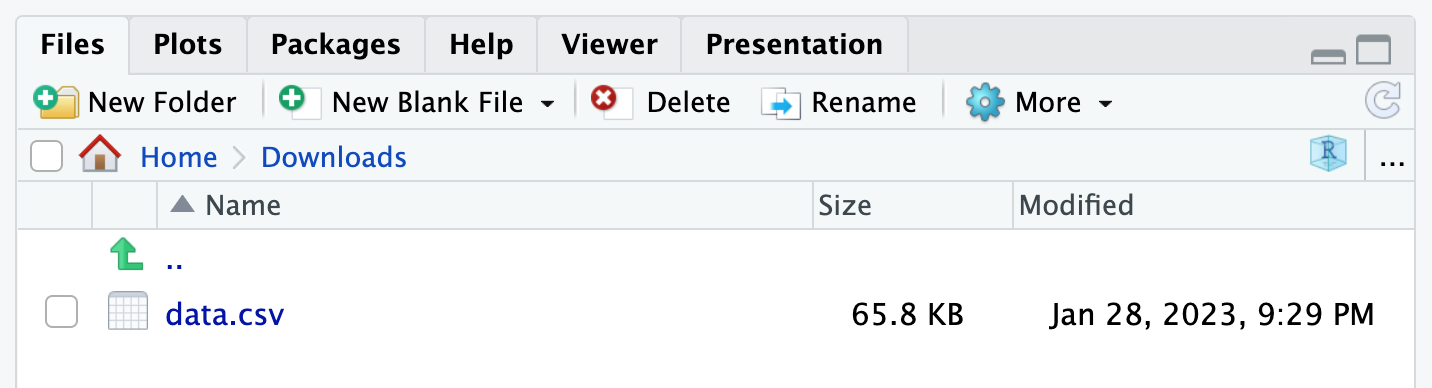
Alternatively, you can move the dataset in the folder where R is currently working (this can be found with getwd()). See more details on importing a file into R and about the working directory.
Another related problem is to use the wrong file. This error is different than the previous ones in the sense that you will not encounter an error but your analyses will still be wrong.
It may sound trivial, but make sure to import and use the correct data file! This is particularly the case if you have files for different points in time and which have a common structure (for example weekly or monthly data files with the exact same variables). It happened to me that I reported results for the wrong week (fortunately, without much consequence).
Also, make sure that you actually use all the rows you want to include in your analyses. It happened to me that, in order to test a model (and avoid long computing times), I extracted a random sample of the original dataset, and almost forgot about this sampling when running my final analyses.
It is thus a good practice to remind you to remove sampling and filters after you have tested your code (and before interpreting the final results).
10. Problem when using the $ operator
For the last error of this top 10, I would like to focus on two related errors:
- “$ operator is invalid for atomic vectors”, and
- “object of type ‘closure’ is not subsettable”.
I gather them in one single section because they are linked to each other in the sense that they both involve the $ operator.
$ operator is invalid for atomic vectors
To understand this error, we first must recall that an atomic vector is a one-dimensional object (usually created with c()). This is different than dataframes or matrices which are two-dimensional (i.e., rows form the first dimension and columns correspond to the second dimension).
The error “$ operator is invalid for atomic vectors” occurs when we try to access an element of an atomic vector using the dollar operator ($):
## define atomic vector:
x <- c(1, 3, 7)
## set names:
names(x) <- LETTERS[1:3]
## print vector:
x## A B C
## 1 3 7## access value of element C:
x$C## Error in x$C : $ operator is invalid for atomic vectorsSolution
The $ operator cannot be used to extract elements in atomic vectors. Instead, we must use double brackets [[]] notation:
x[["C"]]## [1] 7Remember that the $ operator can be used with dataframes, so we can also fix this error by first converting the atomic vector to a dataframe,5 and then access an element by its name with the $ operator:
## convert atomic vector to dataframe:
x <- as.data.frame(t(x))
## print x:
x## A B C
## 1 1 3 7## access value of element C:
x$C## [1] 7object of type ‘closure’ is not subsettable
Another error (which I must admit is quite obscure and confusing when learning R) is the following: “object of type ‘closure’ is not subsettable”.
This error occurs when we try to subset or access some elements of a function. An example with the well-known mean() function:
mean[1:3]## Error in mean[1:3] : object of type 'closure' is not subsettableIn R, we can subset lists, vectors, matrices, dataframes, but not functions. So it throws an error because it is impossible to subset an object of type “closure”, and a function is of that type:
typeof(mean)## [1] "closure"Most of the times, you will not encounter this error when using a basic function such as the mean() function (because it is unlikely that your goal is really to subset a function…).
Indeed, you will most likely face this error when trying to subset a dataset named data, but this dataset is not defined in the environment (because it has not been imported or created properly for instance).
To understand the concept, see the following examples:
## create dataset:
data <- data.frame(
x = rnorm(10),
y = rnorm(10)
)
## print variable x:
data$x## [1] 1.12288964 1.43985574 -1.09711377 -0.11731956 1.20149840 -0.46972958
## [7] -0.05246948 -0.08610730 -0.88767902 -0.44468400So far so good. Now suppose we made a mistake when creating the dataset:
## create dataset (with mistake):
data <- data.frame(x = rnorm(10)
y = rnorm(10))You will notice that a comma is missing between variables x and y. As a result, the dataset named data is not created and thus not defined.
Therefore, if we now try to access the variable x from that dataset data, R will actually try to subset the function named data instead of the dataset named data!
data$x## Error in data$x : object of type 'closure' is not subsettableThis happens because, I repeat, the dataset data does not exist, so R looks for an object named data and find a function with that name:
class(data)## [1] "function"Warnings
Warnings are different than errors in the sense that they alert you about something, but it does not prevent you from running the code. It is a good practice to read these warnings as they may give you valuable information.
There are too many warnings to mention them all, but I would like to focus on two common ones:
- “NAs introduced by coercion”, and
- “Removed … rows containing non-finite values (stat_bin())”.
NAs introduced by coercion
This warning occurs when you try to convert a vector which includes at least one non-numerical value to a numeric vector:
x <- c(1, 3, 7, "Emma")
as.numeric(x)## Warning: NAs introduced by coercion## [1] 1 3 7 NAYou do not need to fix it since it is only a warning and not an error. R is simply informing you that at least one element in the initial vector was converted to NA because it could not be converted to a numeric value.
Removed … rows containing non-finite values (stat_bin())
This warning occurs when you use ggplot2 to draw plots. For instance:
ggplot(airquality) +
aes(x = Ozone) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 37 rows containing non-finite values (`stat_bin()`).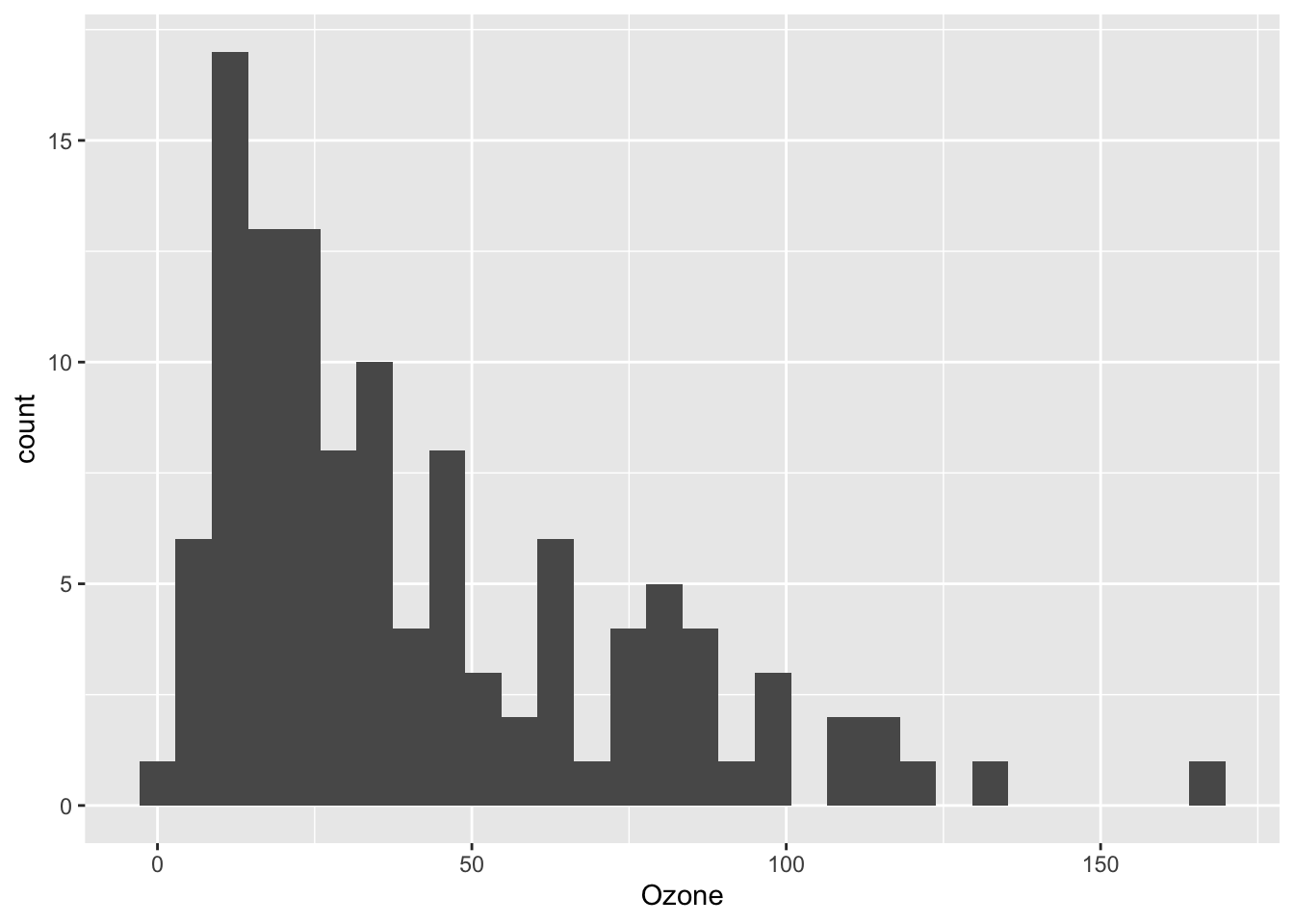
Again, as it is a warning you do not need to fix it. It is simply informing you that there are some missing values (NA) in the variable of interest and that these missing values are removed to construct the plot.
Conclusion
Thanks for reading.
I hope that this collection of errors prevented you from making some coding mistakes, or that it helped you in debugging your code.
If you still cannot fix your error, I would recommend to read the documentation of the function (if you struggle with a function in particular), or look online for the solution. Bear in mind that if you encounter an error, it is very likely that someone else posted the answer online (Stack Overflow is usually a good resource).
R has a steep learning curve, in particular if you are not familiar with another programming language. Nonetheless, with practice and time, you will make less and less coding errors, but more importantly, you will be more and more proficient in typing the right keywords in search engines, resulting in less time spent looking for the solution.
As always, if you have a question or a suggestion related to the topic covered in this article, please add it as a comment so other readers can benefit from the discussion.
There are 2 mistakes in that piece of code, feel free to try to fix them as an exercise.↩︎
And I strongly recommend using RStudio and not just R. See the differences here.↩︎
Note that
mean()applied to a logical variable gives the proportion ofTRUE.↩︎par(mfrow = c(1, 2))is used to put two plots next to each other.↩︎Note that we also need to take the transpose of the vector
xin order to have it as 1 row, 3 columns.↩︎
Liked this post?
- Get updates every time a new article is published (no spam and unsubscribe anytime)
- Support the blog
- Share on:



